The Swedish National Archives (Riksarkivet) has unveiled a new open source solution for transcribing handwritten historical documents, addressing an important cultural challenge for organisations dealing with archival materials.
Developed by the Archives' AI lab (AIRA), the solution includes "Swedish Lion Libre," an AI model trained for Swedish handwriting from 1600-1900, and "HTRflow," a software framework for implementing Handwritten Text Recognition (HTR) and Optical Character Recognition (OCR) projects.
Making Archives Searchable
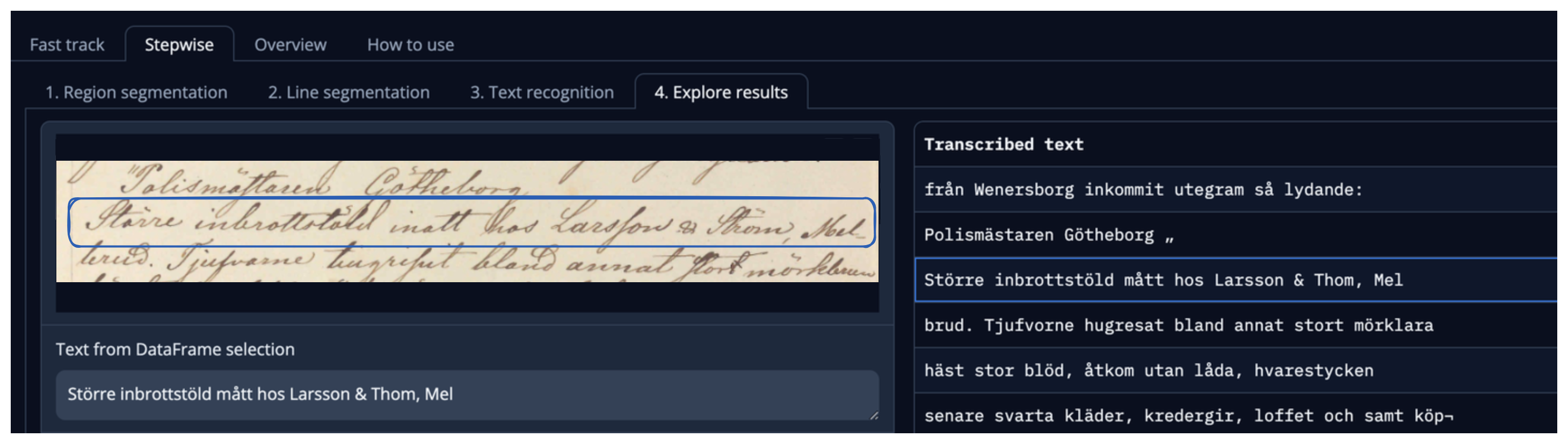
While the National Archives of Sweden preserves extensive digital collections, these materials are currently just images. Handwritten Text Recognition technology enables the automatic conversion of handwritten text into machine-readable format, interpreting the nuances of human handwriting that traditional OCR cannot process.
Features of HTRflow
HTRflow offers:
- Customisable HTR/OCR processing for different materials
- Compatibility with models beyond those developed by the AI lab
- Easy-to-create YAML pipelines
- Multiple export formats (Alto XML, Page XML, text, JSON)
- Tools to compare results with ground truth
The specific model "Riksarkivet/trocr-base-handwritten-hist-swe-2" is trained for handwritten Swedish historical texts and available through Hugging Face.
Open Access
Both components have been released under open licences for free use, modification, and contribution. The National Archives has already implemented these tools internally, demonstrating their practical value.
This initiative represents a significant contribution to digital preservation and accessibility of historical documents. Public administrations across Europe may find these tools valuable for digitisation efforts.
For More Information:
- HuggingFace repositories: https://huggingface.co/Riksarkivet
- HTRflow blog post: https://huggingface.co/blog/Gabriel/htrflow
- Technical documentation: https://ai-riksarkivet.github.io/htrflow/latest/
Picture was reused from the project page.