The National Library of Luxembourg has developed an OCR-tool, that users of historical open data can find pre-trained on GitHub. This software tool is an enhancer of quality of existing XML schema or the regular OCR-engine. It currently comes with a “training set” for the software.
Nautilus-OCR is an open source software tool provided by Bibliothèque nationale de Luxembourg (BnL), the National Library of Luxembourg. BnL started digitalising newspapers back in 2006 by using layout recognition and Optical Character Recognition (OCR). The repository for Nautilus-OCR was created by the reuse of existing open source solutions and it is continuously developed.
Standards for conversion to text
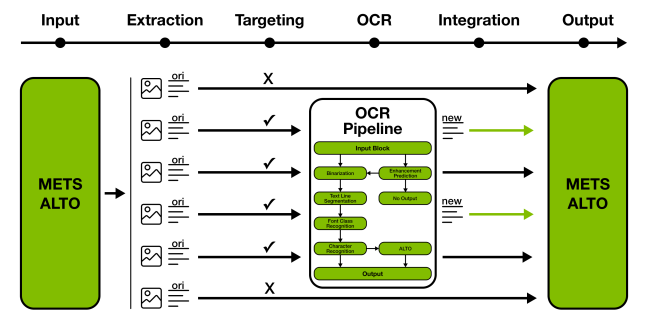
OCR is the digital conversion of images to typed text. It requires excellent image quality to get the best OCR. The library uses the METS/ALTO standard.
Metadata Encoding and Transmission Standard (METS) allows for the exchange of metadata on digitalised documents between heritage institutions. The standard is expressed in XML schema language to create metadata for digital objects, currently maintained by the Library of Congress in the US. Analysed Layout and Text Objects (ALTO) is designed as a European project to store information about content and layout of physical documents.
The Nautilus viewer is created by BnL itself to display METS files with OCR files in ALTO format. It is especially optimised for digitalised newspapers where all layout has been carefully chosen before the original publishing date. METS contains the content while ALTO gives the coordinates of each word.
Enhance quality or use as a regular engine
BnL has digitalised more than 800.000 pages of national newspapers. Using the METS/ALTO standard, BnL can display newspapers with their original layout. This metadata is free to explore for the visitors and visiting researchers at the (digital) library.
According to the Github repository, Nautilus may be used in one of two ways:
- Enhance the OCR quality of METS/ALTO packages.
- Use as a regular OCR engine applied on a set of images.
The tool is written in Python and built on top of several open source libraries including Kraken, TensorFlow and openCV.
The software comes with a training set with more than 33.000 text lines of image and text in different font classes:
The set is based on Luxembourg historical newspapers in the public domain (published before 1878), written generally in German, French and Luxembourgish. Transcription was done using a double-keying technique with a minimum accuracy of 99.95%.
- Description of Train Set bnl-public-ocr, Nautilus-OCR
Final take-aways
- It is possible to obtain and enhance content and the metadata of image/text in old newspapers (in XML-format) through an OCR software component.
- BnL (National Library of Luxembourg) has developed an OCR-tool based on open standards.
- The software is a reuse of several other software tools and can be pre-trained based on 33.000 image/text lines.